Module slow_fir_filter
This document contains technical documentation for the slow_fir_filter module.
This module provides a one-DSP FIR filter implementation. It is suitable for filtering of multiple input channels where the total data rate is significantly slower than the system clock. A key feature is that the channels can be independent from each other, without any known timing relationship between the data. The module also supports multiple coefficient sets, that can be switched in real time.
Downsampling and upsampling is supported. Downsampling is performed after the filter, and upsampling before the filter. Downsampling and upsampling can not be used simultaneously.
The top level to be instantiated by the user is slow_fir_filter, which has these generics:
num_channels: The number of channels.input_data_width: Input data width.num_coefficient_sets: The number of coefficient sets that will be used.num_coefficients_per_set: The number of coefficients of the FIR filter. That is, the order of the filter.coefficients: An integer vector with all coefficients.upsampling: The upsampling factor. Default 1 (no upsampling).downsampling: The downsampling factor. Default is 1 (no downsampling).result_data_width: Size of the result data. If a different width is used than that of the accumulated data, data is either padded or truncated to match. See Data sizing for more information.
Interface
There is an input port, with ready and valid handshake signals, for each channel.
The result data port is the same for all outputs, but each channel has its own
set of handshake signals for the result.
Using AXI4-Stream-like handshake interfaces (ready and valid to qualify data transactions)
is very common in FPGA designs.
It enables a backpressure situation where the slave, i.e. the receiver of data, can indicate when it
is ready to receive the data.
Below are some rules governing how these handshake signals interact. They are adapted from the AMBA 4 AXI4-Stream Protocol Specification, ARM IHI 0051A (ID030610).
A transactions occurs on the positive edge of the clock when both
readyandvalidare high. The graph below shows some typical transactions.
The
readysignal may fall without a transaction having occurred:
The
validsignal may NOT fall without a transaction having occurred:
Once
validis asserted, the associated data may NOT be changed unless a transaction has occurred.
This applies to any auxillary signals associated with the bus as well, e.g. a
lastindicator.Note also that this restriction on data not changing only applies when
validis asserted. When it is not, the data may be changed freely.In order to avoid deadlock situations, the master may NOT wait for the slave to assert
readybefore assertingvalid. The slave however may wait forvalidbefore assertingready.
Data sizing
It is up to the user to set the width such that the desired resource usage is achieved. If the goal is to infer one DSP48E2, the width of the accumulated data must be at most 48 bits.
When not upsampling, the accumulator width is calculated as:
\[\text{accumulator width} = \text{input_data_width} + \left\lceil\log_2 \left(\sum_{n=0}^{n=N-1}|\text{coefficient}_n| \right) \right\rceil\]
, where \(N\) is the number coefficients. This takes into account that the size grows depending on the values of the coefficients, not just the number of coefficients.
This is set by default by the filter, but may be overridden by the user. If a smaller
result_width is set, the lowest significant bits are truncated. The user can get the
default value from the calc_accumulator_width function of the slow_fir_filter_pkg package.
If upsampling is performed, only some of the coefficients will be used each pass, and
calc_accumulator_width takes this into account.
Throughput
The filter uses only one DSP to serve all channels, and most processing cycles are spent calculating the filter taps. There are also a few cycles overhead before a calculation starts.
No resampling
When no up- or downsampling is performed, the number of cycles needed to calculate one output is:
\[\text{cycles per output} = \text{num_coefficients} + 4\]
This assumes that there is always data valid on all inputs, and that the outputs are always ready to accept data.
Upsampling
When upsampling, each input sample results in upsampling number of outputs. These
outputs are calculated directly when the input arrives, before proceeding to the
next channel.
The number of cycles needed to calculate one output is:
\[\text{cycles per output} = \left \lceil{\text{num_coefficients} / \text{upsampling}} \right \rceil + 4\]
Downsampling
When downsampling, only every downsampling inputs results in an output.
The number of cycles needed to calculate one output is the same as when no resampling
is performed:
\[\text{cycles per output} = \text{num_coefficients} + 4\]
Inputs that don’t result in an output still needs to be stored, which consumes four cycles.
macc.vhd

Multiply accumulate (MACC) which automatically clears the accumulated result after a constant number of accumulations. The inputs are two u_signed numbers of any width, and the result width is configurable.
result_widthsets the output width. Truncation is performed if this is smaller than the accumulator width.num_accumulationssets the number of accumulations the MACC performs before resetting to 0.
Resource utilization
This entity has netlist builds set up with
automatic size checkers
in module_slow_fir_filter.py.
The following table lists the resource utilization for the entity, depending on
generic configuration.
Generics |
DSP Blocks |
Total LUTs |
FFs |
|---|---|---|---|
data_a_width = 25 data_b_width = 18 num_accumulations = 1 result_width = 43 |
1 |
< 3 |
< 5 |
data_a_width = 25 data_b_width = 18 num_accumulations = 1 result_width = 47 |
1 |
< 3 |
< 5 |
data_a_width = 25 data_b_width = 18 num_accumulations = 1 result_width = 39 |
1 |
< 3 |
< 5 |
data_a_width = 25 data_b_width = 18 num_accumulations = 7 result_width = 46 |
1 |
< 3 |
< 5 |
data_a_width = 25 data_b_width = 18 num_accumulations = 7 result_width = 50 |
1 |
< 3 |
< 5 |
data_a_width = 25 data_b_width = 18 num_accumulations = 7 result_width = 42 |
1 |
< 3 |
< 5 |
slow_fir_filter.vhd
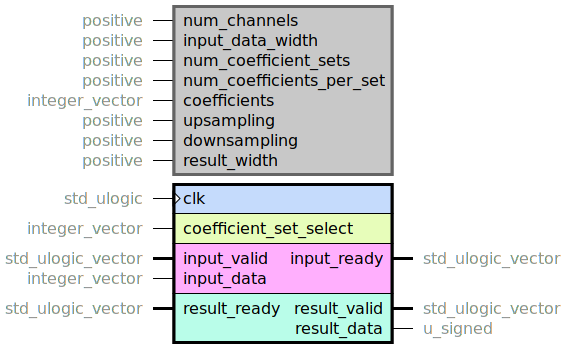
Top level for the slow FIR filter.
The input_data port uses integer_vector instead of an array
unsigned_vector(0 to num_channels - 1)(input_data_width - 1 downto 0)
which would be more suitable. This is due to a bug in GHDL related to unconstrained
arrays in VHDL-2008. For the same reason, the coefficients generic is a one
dimensional vector instead of a matrix. See e.g.
https://github.com/ghdl/ghdl/issues/1224
Resource utilization
This entity has netlist builds set up with
automatic size checkers
in module_slow_fir_filter.py.
The following table lists the resource utilization for the entity, depending on
generic configuration.
Generics |
DSP Blocks |
Total LUTs |
FFs |
RAMB36 |
RAMB18 |
|---|---|---|---|---|---|
num_channels = 1 input_data_width = 25 num_coefficients_per_set = 255 upsampling = 1 downsampling = 1 result_width = 48 (Using wrapper slow_fir_filter_netlist_build_wrapper.vhd) |
1 |
< 150 |
< 100 |
0 |
1 |
num_channels = 1 input_data_width = 25 num_coefficients_per_set = 255 upsampling = 4 downsampling = 1 result_width = 48 (Using wrapper slow_fir_filter_netlist_build_wrapper.vhd) |
1 |
< 150 |
< 100 |
0 |
1 |
num_channels = 1 input_data_width = 25 num_coefficients_per_set = 255 upsampling = 1 downsampling = 4 result_width = 48 (Using wrapper slow_fir_filter_netlist_build_wrapper.vhd) |
1 |
< 150 |
< 100 |
0 |
1 |
num_channels = 4 input_data_width = 25 num_coefficients_per_set = 255 upsampling = 1 downsampling = 1 result_width = 48 (Using wrapper slow_fir_filter_netlist_build_wrapper.vhd) |
1 |
< 200 |
< 100 |
1 |
0 |
num_channels = 4 input_data_width = 25 num_coefficients_per_set = 255 upsampling = 4 downsampling = 1 result_width = 48 (Using wrapper slow_fir_filter_netlist_build_wrapper.vhd) |
1 |
< 200 |
< 100 |
0 |
1 |
num_channels = 4 input_data_width = 25 num_coefficients_per_set = 255 upsampling = 1 downsampling = 4 result_width = 48 (Using wrapper slow_fir_filter_netlist_build_wrapper.vhd) |
1 |
< 200 |
< 100 |
1 |
0 |